Bass and lead guitar, May 27 (trained on 10 MB of bass and lead guitar two-party harmonies):
bass-and-lead-guitar1.mp3
bass-and-lead-guitar2.mp3
bass-and-lead-guitar3.mp3
bass-and-lead-guitar4.mp3
Mozart guitar, June 3 (Many of these pieces start with a short, jagged phrase; I don't know why.)
mozart-guitar-sample1.mp3
mozart-guitar-sample2.mp3
mozart-guitar-sample3.mp3
Carulli guitar, June (Many of these pieces start with a short, jagged phrase; I don't know why.):
Caruli-sample2-Score106-165minutes.mp3
Carulli-sample3-Score106-165minutesb.mp3
Carulli-sample4-Score106-165minutesc.mp3
Carulli-sample6-Score110-179minutescb.mp3
Carulli-sample7-Score99-187minutes.mp3
Carulli-sample8-Score99-187minutesb.mp3
(goodCarulli-sample9-Score99-187minutesc.mp3
)
Mozart, May 26:
mozart2.mp3
mozart3.mp3
mozart4.mp3
mozart5.mp3
mozart6.mp3
mozart7.mp3
mozart8.mp3
Mendelssohn, May 27:
mendelssohn1.mp3
mendelssohn2.mp3
mendelssohn3.mp3
mendelssohn4-modern-sounding.mp3
mendelssohn5.mp3
Bach, May 26:
sample-2018-05-26a.mp3
sample-2018-05-26c.mp3
sample-2018-05-26d.mp3
The Beatles, May 26 (higher numbered, later ones (towards the bottom) sound better, in general):
beatles1.mp3
beatles2.mp3
beatles3.mp3
beatles4.mp3
beatles5.mp3
beatles6.mp3
beatles9.mp3
beatles10.mp3
beatles11.mp3
beatles12.mp3
beatles13.mp3
beatles14.mp3
(theme) beatles15.mp3
beatles16.mp3
beatles17.mp3
beatles18.mp3
beatles19.mp3
beatles20.mp3
beatles21.mp3
beatles22.mp3
Abba, May 27 (Many of them have lots of repeated notes.) :
abba1.mp3
abba2-weird.mp3
abba3.mp3
abba4-repeated-notes.mp3
abba5-repeated-notes.mp3
abba6.mp3
abba7-good.mp3
These some samples are after about an hour of training on a GTX-1070 on Bach MIDI sequences, using two LSTM layers. See further below for three and four layers. They sound better.
Sample26:
Sample27:
Sample28:
Sample29:
Here are three pieces composed from 150MB of pop music harmonies, with two layers of LSTM:
pop1.mp3:
pop2.mp3:
pop3.mp3:
Here are three pieces composed from 150MB of pop music harmonies, with three layers of LSTM (random pieces, no curating):
pop4.mp4:
pop5.mp5:
pop6.mp6:
Here are three pieces composed from bach harmonies, with three layers of LSTM (random pieces, no curating):
bach-three-layers1.mp3:
bach-three-layers2.mp3:
bach-three-layers3.mp3: (This one is good.)
Here are pieces composed from Bach harmonies, with four layers of LSTM (random pieces, no curating). Ones at the start are early in training. Ones at the end are late in training (about 45 minutes later). The loss started at about 390 and went down to about 55+-10. To my ears, these pieces sound more abstract and modern than the Bach pieces composed with three layers.
bach-4layers2.mp3
bach-4layers3.mp3
bach-4layers4.mp3
bach-4layers5.mp3
bach-4layers6.mp3
bach-4layers7.mp3
bach-4layers8.mp3
bach-4layers9.mp3
bach-4layers10.mp3 (This one sounds good, and I hear themes.)
bach-4layers11.mp3
bach-4layers12.mp3
bach-4layers13.mp3 (This one is good too, though it starts slow. I hear variations on what sounds like the Maria theme at varioous places, e.g., at 45 seconds.)
bach-4layers14.mp3
bach-4layers15.mp3
Previous work: melodies only (no harmonies)
MELODL4J is a java package in dl4j-examples for extracting melodies from MIDI, feeding them to a LSTM neural network, and composing music using deep learning.
You train the network on a set of sample melodies. The neural network learns to generate new melodies similar to the input melodies.
During network training, it plays melodies at the end of each training epoch. "Deep humming". At the end of training, it outputs all melodies to a file. There's a utility for listening to the generated melodies.
The LSTM neural network is based on the GravesLSTMCharModellingExample class by Alex Black in deeplearning4j.
The generated melodies are monophonic, meaning that only one note plays at a time: there are no chords or harmony.
The generated melodies do sound pleasant and interesting.
I pursued the project mostly to familiarize myself with deeplearning4j and because it's cool. I hope the example is educational and fun for others, as well as a foundation for doing more complex musical composition.
There were 6921 training melodies (about 5MB uncompressed) for the pop music training, for which were 541,859 parameters in the LSTM network. For the bach training, there were 363 input melodies. Perhaps the network memorized some snippets.
To help judge the extent to which generated melodies mimic existing melodies in the input training set, I wrote a utility to find the longest approximate string match between two melody strings. Using that utility, I found a melody closest to the first melody of http://truthsite.org/music/melodies-like-bach.mp3. Both that first melody (snippet) and the Bach melody closest to it are in
http://truthsite.org/music/closest-matches1.mp3. Judge for yourself whether the neural network is mimicing Bach. I think it's similar but not a copy.
Overview of methodology, simplifications, and tricks
Midi2MelodyStrings.java parses MIDI files and outputs melodies in symbolic form.
Given a Midi file, Midi2MelodyStrings.java outputs one or more strings representing the melodies appearing in that midi file.
If you point Midi2MelodyStrings.java at a directory, it processes all midi files under that directory. All extracted melodies are appended to a single output file.
Each melody string is a sequence of characters representing either notes (e.g., middle C), rests, or durations. Each note is followed by a duration. Each rest is also followed by a duration.
There is a utility class, PlayMelodyStrings.java, that converts melody strings into MIDI and plays the melody on your computer's builtin synthesizer (tested on Windows).
To limit the number of possible symbols, the program restricts pitches to a two-octave interval centered on Middle C. Notes outside those two octaves are moved up or down an octave until they're inside the interval.
The program ignores gradations of volume (aka "velocity") of MIDI notes. It also ignores other effects such as pitch bending.
For each MIDI file that it processes, and for each MIDI track appearing in that file, Midi2MelodyStrings outputs zero or more melodies for that track.
The parser skips percussion tracks.
To exclude uninteresting melodies (e.g., certain bass accompaniments or tracks with long silences) the program skips melodies that have too many consecutive identical notes, too small a variety of pitches, too much silence, or too long rests between notes.
For polyphonic tracks, the program outputs (up to) two monophonic melodies from the track: (i) the top notes of the harmony and (ii) the bottom notes of the harmony.
A monophonic track results in a single output melody.
The sequence of pitches in a melody is represented by a sequence of intervals (delta pitches). Effectively, all melodies are transposed to a standard key.
To handle different tempos, the program normalize all durations relative to the average duration of notes in the melody.
The program quantizes tempos into 32 possible durations: 1*d, 2*d, 3*d, .... 32*d, where d is 1/8th the duration of the average note. Assuming the average note is a quarter note, the smallest possible duration for notes and rests is typically a 1/32nd note.
The longest duration for a note or a rest is four times the duration of the average note. Typically, this means that notes longer than a whole note are truncated to be a whole note in length.
No attempt is made to learn the characteristics of different instruments (e.g. pianos versus violins).
MelodyModelingExample.java is the neural network code that composes melodies. It's closely based on GravesLSTMCharModellingExample.java by Alex Black.
At the end of each learning epoch, MelodyModelingExample.java plays 15 seconds of the last melody generated. As learning progresses you can hear the compositions getting better.
Before exiting, MelodyModelingExample.java writes the generated melodies to a specified file (in reverse order, so that the highest quality melodies tend to be at the start of the file).
The melody strings composed by the neural network sometimes have invalid syntax (especially at the beginning of training). For example, in a valid melody string, each pitch character is followed by a duration character. PlayMelodyStrings.java will ignore invalid characters in melody strings.
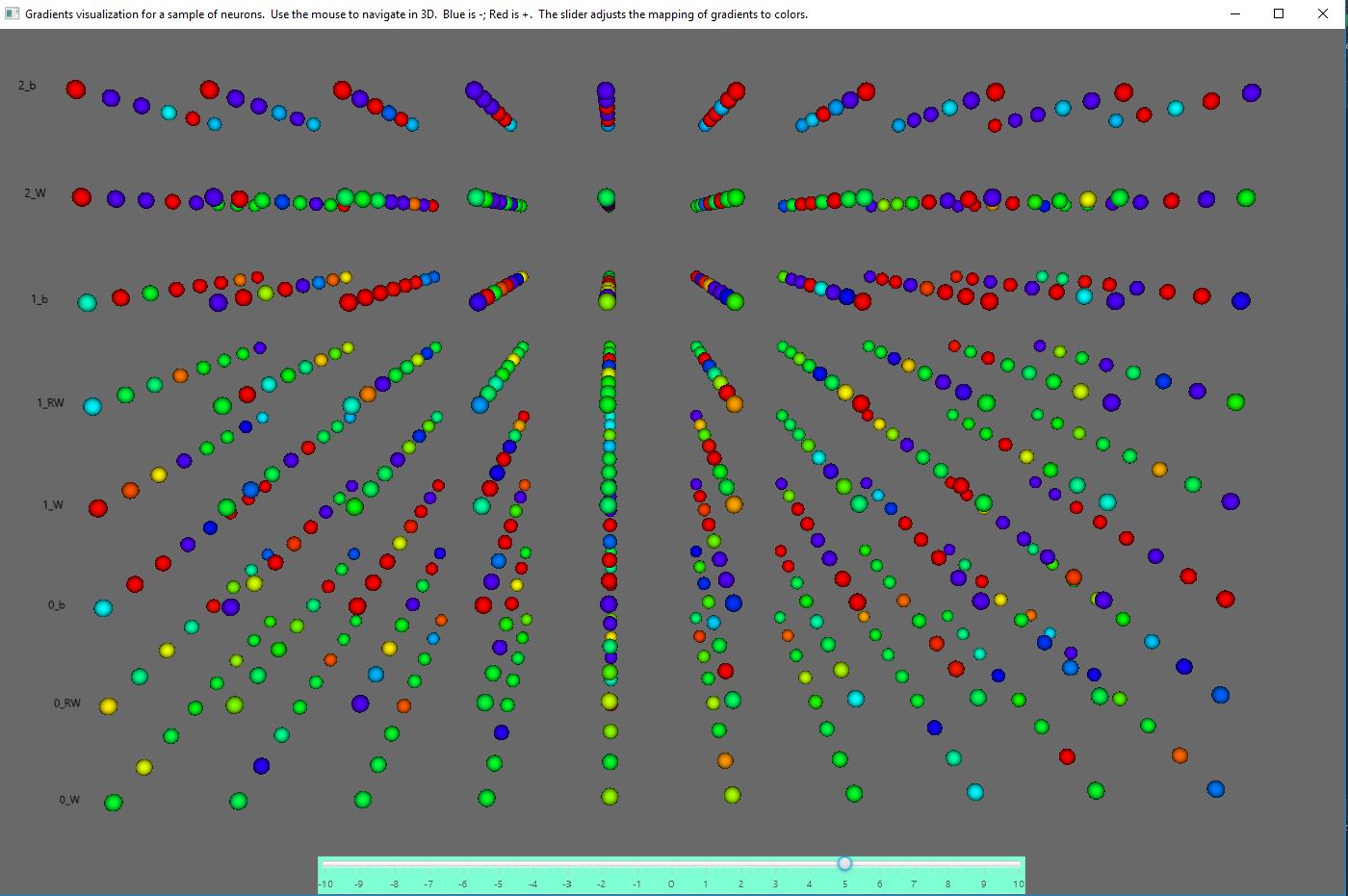
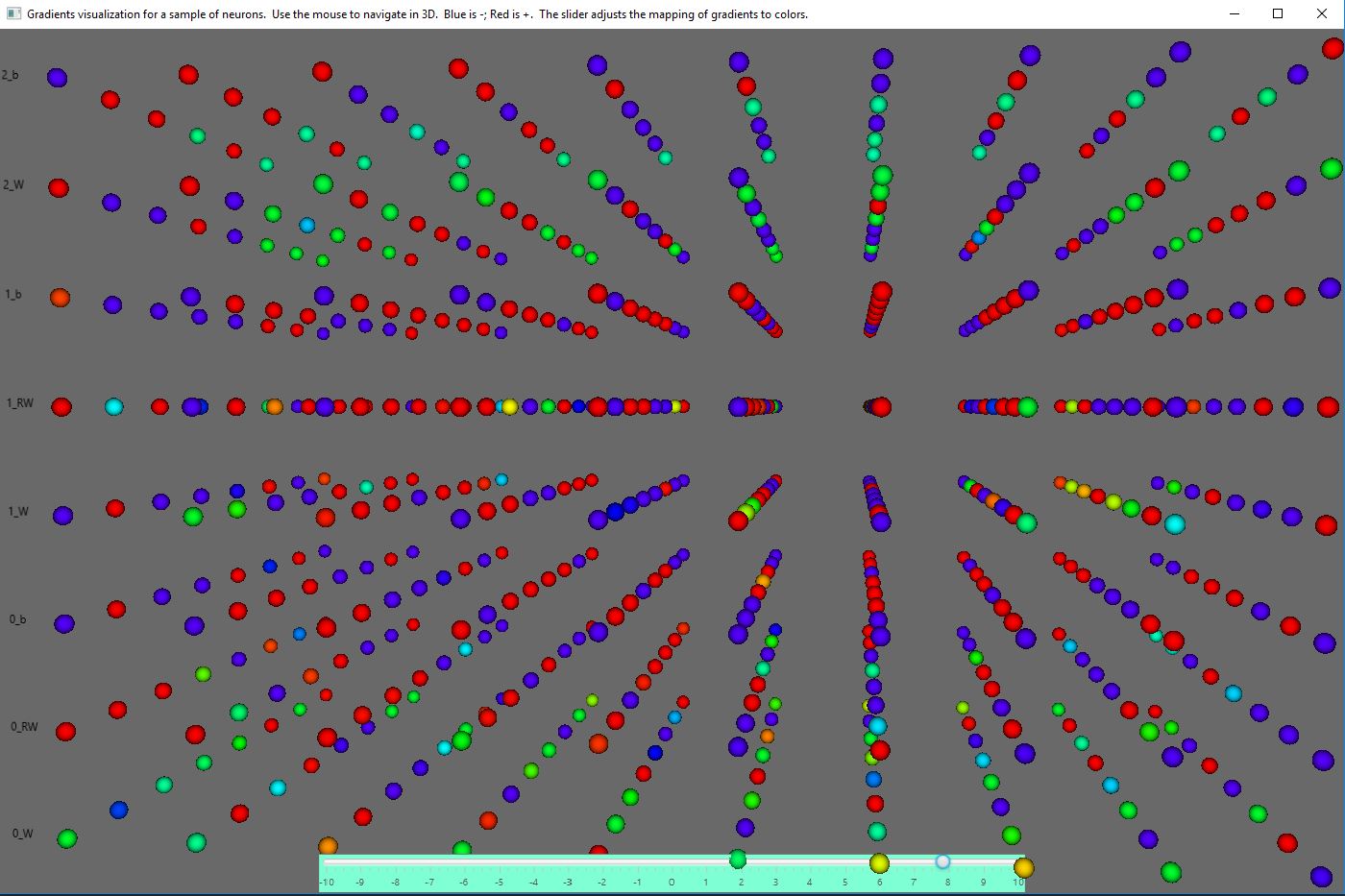
Real-time 3d visualization of gradient changes in a sample of neurons in each layer of the neural network
Using JavaFX and a TrainingListener of deeplearning4j, I made classes to visualize the gradients of the neural network in real time as it learns. Here are some screen shots.
The slider at the bottom lets you control (on a logarithmic scale) the sensitivity of the mapping from gradients to colors.
You can configure the number of neurons whose gradients are shown. Neurons are chosen randomly from each layer up to the number you specify in the configuration.
Each Layer of the MultiLayerNetwork results in two "layers" (levels) of the visualization: one for the weights and one for the biases.
I expect that visualizing the gradients will greatly help understand how networks learn or don't learn.
Possible directions for improvement
Represent durations numerically, not symbolically. Currently, both pitches and durations are represented symbolically (as characters), not numerically. This makes sense for pitches probably, since the qualitative feel of a C followed by a G is quite different from the qualitative feel of a C followed by a G#. Likewise, following a C, a G is more similar to a E than to a G#; both E and G are notes in a C major chord. But for tempos, a 32d note is more similar to a 16th note than to a quarter note, etc.
Explore different activation functions, numbers of layers, and network hyper-parameters.
Handle gradations of volume, as well as other effects such as vibrato and pitch bend.
Learn different melodies for different instruments.
Make an interactive app that lets you "prime" the neural network with a melody -- via a real or virtual (piano) keyboard -- similar to generationInitialization in GravesLSTMCharModellingExample.
Enhance the MIDI parser and make a DataVec reader.